


Data in the Age of AI
We live in interesting times.

Introduction
How does the sudden explosion in AI affect data and data businesses?
In this essay I present two answers and explore their implications:
A material change in the relative values of information and compute, with implications for both software and data business models.
An even more dramatic change in the absolute quantities of data and compute available in the world, with implications for trust, identity, quality and curation.
But I’ll begin with some history. Data and data loops are the key driver of the best performing business models of the last decade, and through them, of the AI revolution itself. Let’s find out how!
Memory is Destiny
I taught myself to code on a IBM PC clone running MS-DOS on an 8086. This was in the late 80s; the computer was cheap, functional and remarkably ugly, but it worked. And it had what was — for its time — a princely amount of storage: 30 whole megabytes of hard disk space.
A decade later, working my first job as a programmer, storage was easier to come by, but it was never out of my mind. I cared about memory leaks and access times and efficiency. Creating a clever data structure to hold yield curves for rapid derivatives pricing was one of my prouder achievements at the time. We didn't store everything, only what we needed to.
Another decade later, I just didn't care. At Quandl, the startup I founded, we saved everything. Not just the data assets that formed the core of our business, with all their updates and vintages and versions, but also all our usage logs, and API records, and customer reports, and website patterns. Everything.
What happened? Well, this:
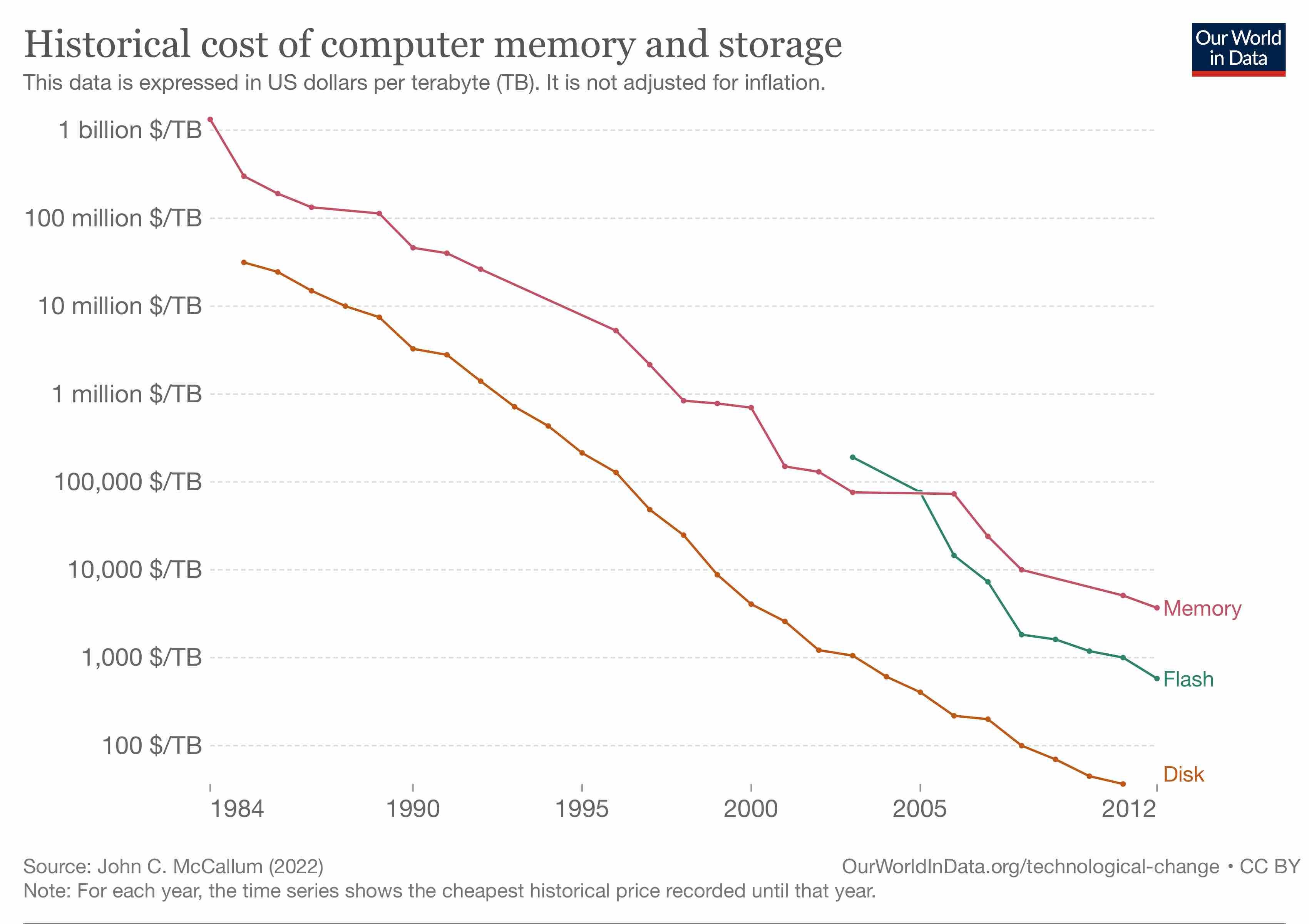
The Data Explosion …
Quantitative changes that result in qualitative changes are always worth watching. Because it wasn't just Quandl that stored all its data; it was everyone. Everyone everywhere, all at once.
The 2010s were the decade of the data explosion. Driven by falling hardware costs, and — equally as important — by business models that made said hardware easy to access (shoutout to Amazon S3!), the world began to create, log, save, and use more data than ever before.
… and Business Models
A huge number of the business models that ‘won’ the last decade are downstream of the data explosion:
the entire content-adtech-social ecosystem
the entire ecommerce-delivery-logistics ecosystem
the infrastructure required to support these ecosystems
the devtools to build that infrastructure
How so?
Consider advertising, still the largest economic engine of the internet. Facebook, Reddit, Youtube, Instagram, Tiktok and Twitter all rely on the exact same loop, linking users, content and advertisers:
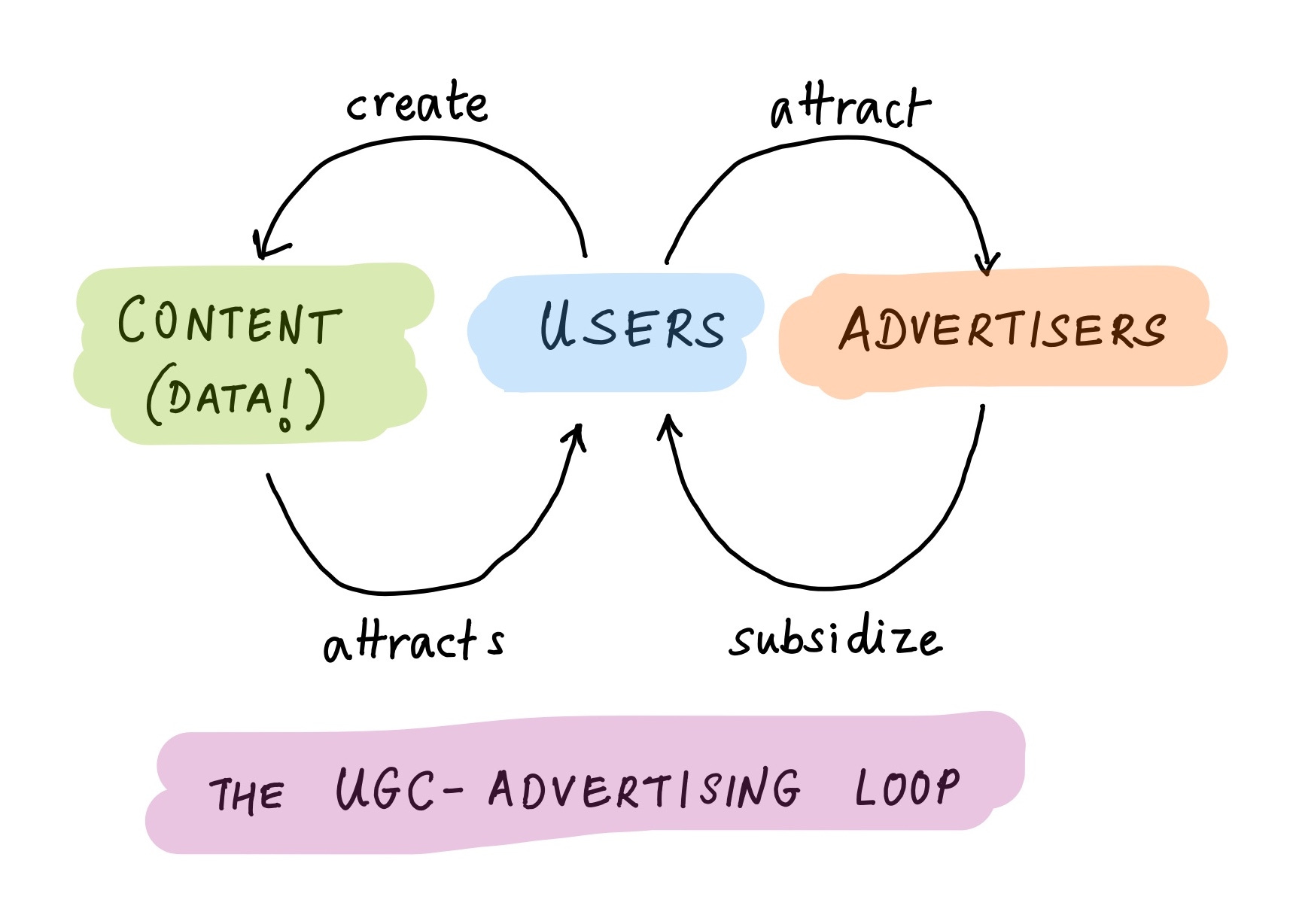
Companies are able to offer users unlimited free storage for photos, videos, blog posts, updates and music; the content attracts more users, who attract advertisers, who subsidize the platform, and the cycle continues. None of this is possible without cheap, plentiful storage.
Or consider delivery and logistics. It's easy to take for granted today, but the operational chops required to power same-day e-commerce, or ride-sharing, or global supply chains, are simply staggering. The famous Amazon and Uber flywheels are just special cases of a data learning loop:
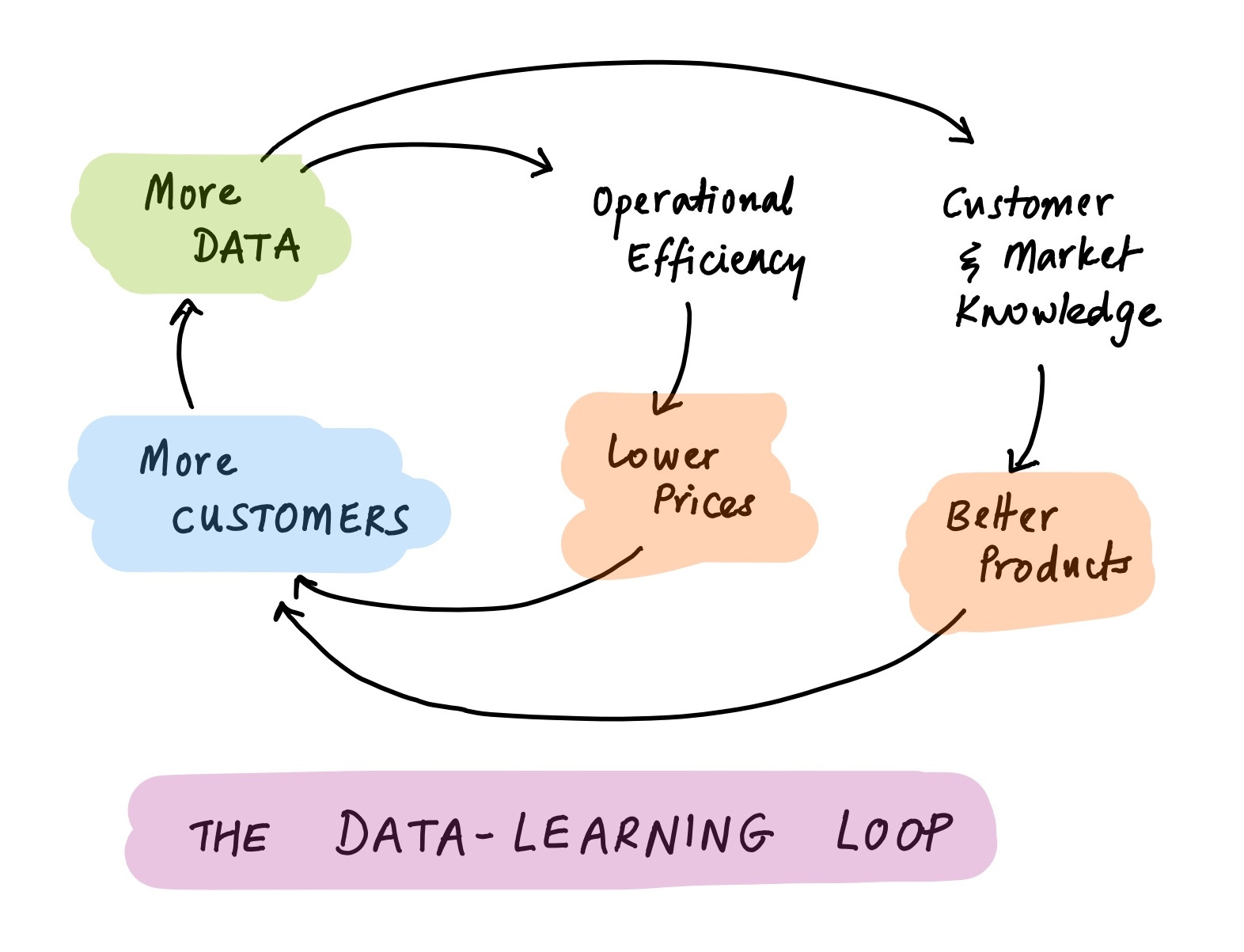
These flywheels require up-to-date knowledge of customer locations, purchase and travel habits, store inventories and route geographies, driver and car availability, and a whole lot more. Again, none of this is possible without cheap, plentiful data1.
Note, incidentally, that all these flywheels are not just powered by data; they generate new data in turn. The data explosion is not just an explosion; it's a genuine chain reaction. Data begets data.
Data Is Software’s Best Friend
All these business models are, essentially, software. And that's no surprise! Data and software are two sides of the same coin.
The software used to optimize businesses is useless without data to apply itself to. And data is worthless without software to interpret and act on it.
More generally, tools are useless without materials; materials don't have value unless worked on with tools.
Complementary Inputs
Economists call these ‘perfectly complementary inputs’: you need both to generate the desired output, and you can't substitute one for the other. An immediate consequence is that if the price of one input falls by a lot — perhaps due to a positive productivity shock — then the price of other is almost certain to rise.
Imagine you're a tailor. To sew clothes, you need needles and fabric, and you're limited only by the quantity of each of those you can afford. (Needles and fabric are complementary inputs to the process of sewing).
Now imagine that the price of needles plummets, due to a new needle-manufacturing technology. Your response? Use the savings to buy more fabric, and thus sew more clothes! But if every tailor does this, then the price of fabric will rise. Tailors and consumers are both better off, the total quantity of clothing produced goes up, but the relative value of needles and fabric has changed.For the last decade plus, the quantity of data in the world has been exploding: its price, therefore, implicitly declining. Software has been the relatively scarce input, and its price has increased: you can see this in everything from the salaries of software engineers to the market cap of top software companies. Software ate the world, with a huge assist from cheap, plentiful data.
And then came GPT, and everything changed.
The Peace Dividend of the Content Wars
GPT is a child of the data explosion. The flood of new data, generated by users but also by content farms and click factories and link bots and overzealous SEO agencies, necessitated the invention of new techniques to handle all that data. And it was a team of researchers at Google who wrote Attention is All You Need, the paper that introduced the Transformers architecture underlying pretty much every modern generative AI model.
The original peace dividend was that of the Cold War. Transistors, satellites and the internet were all offshoots of that conflict; today, they're used for more — far more — than just launching and tracking missiles. Similarly, although LLMs were invented to manage the data spun off by the Content Wars, they’re going to be used for a lot more than just Search.
The Compute Explosion
GPT is prima facie a massive productivity boost for software. Technologists talk about the 10x programmer: the genius who can write high-quality code 10 times faster than anybody else. But thanks to GPT, every programmer has the potential to be 10x more productive than the baseline from just 2 years ago.
We are about to see the effects.
Move over data explosion; say hello to the compute explosion!
Data Rules Everything Around Me
The first and perhaps most obvious consequence of the compute revolution is that data just got a whole lot more valuable.

This naturally benefits companies who already own data. But what’s valuable in an AI world is subtly different from what was valuable in the past.
Some companies with unique data assets will be able to monetize those assets more effectively. BloombergGPT is my favourite example: it’s trained on decades of high-quality financial data that few others have. To quote a (regrettably but understandably anonymous) senior exec in the fin-data industry: “Bloomberg just bought themselves a twenty year lease of life with this”.
Other companies will realize that they are sitting on latent data assets — data whose value was unrecognized, or at any rate unmonetized. Not any more! Reddit is a good example: it's a treasure trove of high-quality human-generated content, surfaced by a hugely effective moderation and upvoting system. But now you have to pay for it.
You don't need huge content archives or expensive training to get meaningful results. Techniques like LoRA let you supplement large base models with your own prop data at relatively low cost. As a result, small custom data can hold a lot of value.
Quantity has a quality that’s all its own, but when it comes to training data, the converse is also true. ‘Data quality scales better than data size’: above a certain corpus size, the ROI from improving quality almost always outweighs that from increasing coverage. This suggests that golden data — data of exceptional quality for a given use case — is, well, golden.
Picks and Shovels, Deals and Steals
The increasing value of data has some downstream implications. In a previous essay, I wrote about the economics of data assets:
The gold-rush metaphor may be over-used, but it’s still valid. Prospecting is a lottery; picks-and-shovels has the best risk-reward; jewellers make a decent living; and a handful of gold-mine owners become fabulously rich.
The very best data assets, reshaped for AI use cases, are the new gold mines. But there are terrific opportunities for picks-and-shovels specifically designed around the increased salience of data in an AI-first world:
tools to build new data assets for AI;
tools to connect existing data assets to AI infra;
tools to extract latent data using AI;
tools to monetize data assets of every sort.
More generally, the entire data stack needs to be refactored, such that generative models become first-class consumers as well as producers of data. Dozens of companies are emerging to do precisely this, from low-level infra providers like Pinecone and Chroma, to high-level content engines like Jasper and Regie, to glue layers like LangChain, and everything in between.
Quite apart from tooling, there's an entire commercial ecosystem waiting to be built around data in the age of AI. Pricing and usage models, compliance and data rights, a new generation of data marketplaces: everything needs to be updated. No more ‘content without consent’; even gold-rush towns need their sheriffs.
High-value information assets; a new generation of picks-and-shovels; a reimagined ecosystem for data: the world of data business just got a lot more interesting!
An Accelerating Flywheel
The second major consequence of AI is that the quantity of both data and compute in the world is going to increase dramatically. There’s flywheel acceleration: data feeds the compute explosion and compute feeds the data explosion. And there’s also a direct effect: after all, generative models don't just consume data; they produce it.
Right now the output is mostly ephemeral. But that's already changing, as ever more business processes begin to incorporate generative components.
What does this imply for data?
The Confidence Chain
We’re entering a world of unlimited content. Some of it is legit, but much of it isn’t — spam bots and engagement farmers, deep fakes and psyops, hallucinations and artefacts. Confronted with this infinite buffet, how do you maintain a healthy information diet?
The answer is the confidence chain — a series of proofs, only as strong as its weakest link. Who created this data or content; can you prove that they created it; can you prove they are who they say they are; is what they created ‘good’; and does it match what I need or want? Signatures, provenance, identity, quality, curation.
The first three are closely linked. Signatures, provenance and identity: where does a something really come from, and can you prove it? After all, “on the internet, nobody knows you’re an AI”. Technologically, this space remains largely undefined, and therefore interesting. (The irony is that it’s an almost perfect use case for zero-knowledge crypto — and crypto has been utterly supplanted in the public imagination by AI.)
The last two are also closely linked. Curation is how quality gets surfaced, and we’re already seeing the emergence of trust hierarchies that achieve this. Right now, my best guess at an order is something like this:
filter bubbles > friends > domain experts ~= influencers > second-degree connections > institutions > anonymous experts ~= AI ~= random strangers > obvious trolls
But it's not at all clear where the final order will shake out, and I wouldn’t be surprised to see “curated AI” move up the list.
A nuance that often gets lost here is that curation is not about ranking; it's about matching. If generative AI increases the total volume of content in the world 100x, that does not imply that your quality filter needs to be 1/100 as restrictive. There's no ‘law of conservation of quality’; no upper limit to the number of high-quality creations possible. The limiting factor is your bandwidth as a consumer of content.
Hence the goal of curation is not to rank the ‘best’ X of any category, but rather to find the X that (conditional on a minimum quality cutoff) best matches your profile. (And your profile may not be neutral or objective; this is why filter bubbles are at the very top of the trust hierarchy.)
(Note that the entirety of this section is applicable to B2B use cases and a wide range of data types, not just consumer use cases and social content.)
Compute All The Things
Data becomes more valuable; ecosystems need to be retooled; the data explosion will accelerate; and trust chains will emerge. What about compute itself?
Just like the default behaviour for data flipped from ‘conserve memory’ to ‘save everything’, the default behaviour for software is going to flip to ‘compute everything’.
What does it mean to compute all the things? Agents, agents everywhere. We used to talk about human-in-the-loop to improve software processes; increasingly, we're going to see software-in-the-loop to streamline human processes. This manifests as AI pilots and co-pilots, AI research and logistics assistants, AI interlocutors and tutors, and a plethora of AI productivity apps.
Some of these help on the data/content generation side; they’re productivity tools. Others help on the data/content consumption side; they’re custom curators, tuned to your personal matching preferences.
More pithily, if you’re a Neal Stephenson fan:

An open question is whether these agents will compress or magnify current differentials in power, wealth and access. Will the rich and famous have better AI agents, and get even richer and more famous compared to the masses? History suggests not; that productivity is a democratizer; but you never know.
New Abundance, New Scarcity
The 19th century British economist William Jevons observed a paradox in the coal industry. Even though individual coal plants became more efficient over time — using less coal per unit of energy produced — the total amount of coal used by the industry did not decline; it increased. Efficiency lowered the price of coal energy, leading to more demand for that energy from society at large.
Something very similar is happening with the data-software complex. It’s not just that data and software reinforce each other in a productivity flywheel. It’s not just that generative models produce and consume data, produce and consume code. It’s that the price of ‘informed computation’ has fallen, and the consequence is that there will be a lot more informed computation in the world.
A possibly lucrative question to ask is, where are the new areas of scarcity? The hardware that powers compute and data is an obvious candidate: as the latter exponentiate, the former cannot keep up. Persistent and recurring chip shortages are a symptom of this; my hypothesis is that this is not a problem of insufficient supply, it’s a problem of literally insatiable demand, driven by the Jevons effect.

Another candidate for scarcity is energy. Large model training consumes a huge amount of energy, but at least it’s confined to a few firms. But once you add in accelerating flywheels, the compute explosion and agents everywhere, the quantities become vast. We haven’t felt the pinch yet because of recent improvements in energy infra — solar efficiency, battery storage and fracking — and there’s hope that informed compute will help maintain those learning curves.
Watch out for artificial scarcity. Society may benefit from abundance, but individuals and corporations have different incentives; they make seek to constrain or capture the gains from ubiquitous, cheap, powerful data and computation.
Finally and most provocatively, what happens to human beings in this brave new world? Are we a scarce and valuable resource, and if so why — for that nebulous entity we call ‘creativity’, or for our ability to accomplish physical tasks? Will AI augment human capacity, or automate it away? I believe in abundance and I’m optimistic; the only way to find out is to go exploring. We live in interesting times!
Toronto, 16 May 2023.
End Notes and Requests
If you found this essay thought-provoking, please share it — on social media, with friends, enemies, or anyone else you think might enjoy it.
Please subscribe to my newsletter, Pivotal. I write essays on data, investing, and startups. My essays are infrequent, usually in-depth, and hopefully insightful. Also, they’re free.
Writing in public is an exercise in ‘tapping a tuning fork and seeing who resonates’. If this essay resonated with you, come and say hi!
I’m an active angel investor in tech startups, many of whom fit the templates of companies described in today’s essay:
If you’re building a company along similar lines, I’d love to hear from you.
[Off-topic] Is high-quality preference-matched content really that valuable? To test this hypothesis, I’ve written a curated guide to visiting Japan. If you like my essay, you might like this guide: it’s selective, deep and informed. Check it out!
Free services from the UGC-advertising loop and lower prices from the data-learning loop are both deflationary. Therefore, ZIRP was a zero-cost-of-data phenomenon!